리서처들이 매일 쓰는 사내 퀀트 분석 플랫폼. 어느 날부터 서버가 터지기 시작했어요.
NiceGUI로는 더 이상 안 됐고, React로 옮겨야 했어요. 처음 받은 견적은 3주.
실제로는 5일에 끝났어요. 중간에 Next.js를 버리고 Vite로 꺾는 결정까지 포함해서요.
배경: 제가 처음부터 만든 건 아니었어요
먼저 팀이 이렇게 생겼어요.
- 퀀트 리서처 4명 (Python 전략 알고리즘)
- 백엔드 1명 (본부장)
- 기획 1명 (저)
프론트엔드 개발자 0명, 디자이너 0명.
AED 백테스팅 엔진이랑 분석 파이프라인은 회사에 이미 있었어요. 그 위에 화면을 덮은 건 본부장님이었어요. Claude Code로 대충 구현해서 리서처 3~4명이 쓰고 있었죠. “쓸 만하지만 진짜 도구라고 하기엔…” 정도의 상태가 2025년 10월부터 이어지고 있었어요.
2026년 1월부터 제가 프론트엔드를 손보기 시작했어요. 리서처들 사이에서 “이거 이렇게 보면 좋겠다”, “이 화면에 이것도 있어야 하지 않나?” 같은 요구가 쌓이기 시작했거든요. “기획자가 코드도 짜?”라는 질문에는 “안 짜면 아무도 안 짜는데요”라고 답하는 수밖에 없는 상황이었어요.
NiceGUI, 작을 땐 더없이 좋았어요
처음 쓴 건 NiceGUI였어요. 이유는 단순했어요.
- 백엔드 팀이 전부 Python. 스택을 쪼개지 말자
- 저도 JavaScript보다 Python이 편했어요
- Quasar 기반이라 컴포넌트도 제법 있었고요
몇 달 동안은 잘 굴러갔어요. 페이지를 하나씩 더 만들고, 디자인을 조금씩 다듬고, 기능도 누적됐어요. 3~4명이 쓸 땐 가볍고 반응도 괜찮았어요.
문제가 없던 건 아니었어요. 디자인 시안을 옮기면 70%만 재현됐고, 복잡한 인터랙션은 우회해야 했고, 다크 모드와 다국어는 매끄럽지 않았어요. 그래도 “이 정도면 쓸 만하다” 범주 안이었어요. 사실 이 시점부터 이미 React 이주는 계획에 있었어요. 당장은 아니고, 언젠가.
서버가 터졌어요
그 “언젠가”가 훨씬 빨리 왔어요.
내부에서 AED를 쓰는 사람이 늘기 시작했어요. 기능도 계속 추가됐고요. 어느 순간부터 NiceGUI 서버가 쉽게 터지는 문제가 생겼어요. 그냥 느린 게 아니라, 리서처 몇 명이 동시에 백테스트 결과를 열면 응답이 안 오는 수준이요.
3~4명일 땐 문제가 아니었던 게, 사용자 수 × 기능 수 × 데이터 양이 누적되니까 한계를 넘어버렸어요. 우회로 버틸 수 있는 단계는 이미 지나있었고요. 이주를 더 미룰 수 없었어요.
3주짜리 견적
React로 가기로 정하고 나서 처음 잡은 견적은 3주였어요. 이유는 간단했어요.
20+ 페이지. 라우팅, i18n, 차트, 테이블, 다크 모드, 다국어. 전부 재작성이에요.
기획자 한 명이 이걸 평범한 속도로 해내면 3주는 잡아야 한다고 본 거예요. 그리고 첫 타겟은 Next.js였어요. React 생태계에서 가장 무난한 기본값이니까요. 레퍼런스 많고, 풀스택 지원, 디자인 시스템 생태계(shadcn, Tailwind)가 풍부하고요.
근데 견적 3주와 실제 5일 사이에 격차가 생긴 이유는, 이주 작업을 시작하기 전에 이주가 쉬워지는 것들을 먼저 만들어뒀기 때문이었어요.
3주를 5일로 줄인 세 가지
1. Living PRD: 코드 대신 읽을 수 있는 “왜”
NiceGUI 시절에 저는 각 페이지마다 PRD를 작성하고 있었어요. 그냥 처음에 한 번 쓰고 끝내는 기획서가 아니라, 구현하면서 내린 결정이 PRD로 역류하게 만들었어요.
예를 들어 “이 테이블에서 태그 몇 개까지 보여줄 것인가?”라는 질문에 처음엔 “5개”로 썼다가, 실제로 구현해보니 부족해서 “10개”로 바꿨어요. 이때 코드만 고치는 게 아니라 PRD도 같이 고치고, “왜 바꿨는지”를 같이 기록했어요. 이런 식이요.
MAX_VISIBLE_TAGS: 10 (변경: 5는 구현 중 너무 적은 것을 확인)
이게 이주할 때 왜 중요하냐면, 옮길 때 제가 참고하는 게 코드가 아니라 PRD가 됐거든요. 코드엔 “어떻게”가 있지만, PRD엔 “왜”가 있어요. 옮길 땐 “왜”만 알면 새 프레임워크에 맞게 “어떻게”는 다시 짜면 되거든요. 한 달치 결정이 PRD에 전부 기록돼 있으니까, 이주 때 “이거 왜 이렇게 되어 있었지?”로 낭비되는 시간이 없었어요.
2. mockup-apply 스킬: 반복 작업을 프롬프트 한 번으로
제가 만든 Claude Code 스킬 중에 mockup-apply라는 게 있어요. HTML 목업을 기존 페이지에 적용할 때, 변경 체크리스트(ADD/CHANGE/KEEP)를 자동으로 뽑고, 기존 기능은 보존하면서 새 UI만 덧씌우는 워크플로우예요.
원래는 디자인 개선용으로 만든 건데, 이주에도 그대로 쓸 수 있었어요. 입력을 NiceGUI 페이지 스펙으로 바꾸고, 출력을 React 컴포넌트로 바꾸기만 하면 됐거든요. 한 페이지씩 수작업으로 옮길 때 들어가는 “컬럼 순서 맞추고, 이벤트 핸들러 이름 맞추고, 조건부 렌더링 누락 없이 옮기고…” 같은 피로가 대부분 이 스킬에서 해결됐어요.
3. CSS 변수 토큰: 프레임워크 독립적인 디자인
NiceGUI 시절부터 저는 색상, 간격, 타이포를 전부 CSS 변수로 정의해뒀어요.
--bg-page: #FBF9F9;
--bg-card: #FFFFFF;
--accent-blue: #2D4A5A;
--accent-emerald: #2B6951;
토큰 이름을 의미 기반으로 쓴 게 핵심이에요. --blue-600 같은 수치 기반이 아니라 --accent-blue 같은 의미 기반.
덕분에 React로 옮길 때 이 토큰 파일을 그대로 복사하면 됐어요. 컴포넌트 코드는 바뀌지만, 디자인은 자동으로 따라왔어요. 나중에 Editorial Precision 컬러 팔레트로 톤을 바꿀 때도, 컴포넌트 코드 한 줄 안 바꾸고 전체가 새 톤으로 이동했고요.
5일 스프린트, 그리고 중간에 꺾은 한 번의 결정
실제로 5일 동안 일어난 일은 이래요.
처음에 Next.js로 옮기는 작업을 시작했어요. Living PRD + mockup-apply + CSS 토큰 조합이 진짜 말이 되게 빨랐어요. 한 페이지 옮기는 데 몇 시간씩 걸릴 줄 알았는데, 대부분 한 시간 이내였어요. “3주 견적이 과했나?”라는 생각이 점점 들기 시작했어요.
”잠깐, 우리 SSR 하나도 안 쓰는데?”
옮기는 중에 문득 이상한 걸 깨달았어요. AED는 전부 인증 뒤의 대시보드예요. SEO 필요 없고, 공개 페이지 없고, 모든 페이지가 "use client"로 선언돼 있었어요.
Next.js의 핵심 가치(SSR, ISR, 서버 컴포넌트)를 단 한 페이지도 쓰고 있지 않았어요.
SSR 준비 비용만 그대로 떠안고, 이점은 0. 한마디로 과잉이었던 거예요. “트렌드니까 썼다”는 게 부끄러운 순간이었어요.
본부장님한테 “우리 Vite로 가는 게 낫지 않을까요?” 꺼냈어요. 측정 결과도 같이 들고요.
| 지표 | Next.js 16 | Vite 8 |
|---|
build | 8s | 741ms |
| Dev server start | 5s | 150ms |
| HMR | 2s | 즉시 |
본부장님도 같은 느낌을 받고 계셨고, 옮기자고 결정됐어요. 1인 풀스택 환경이라도 결정을 혼자 내리는 건 아니에요. 공감하는 사람이 한 명만 있으면 움직이기 시작해요.
실제 전환은 “프롬프트 한 줄”
Next.js에서 Vite로 옮기는 건 큰 작업이 아니었어요. 이주의 본체는 이미 끝나가고 있었거든요. 남은 건 이 정도였어요.
- 라우팅: App Router → React Router v6
- i18n:
next-intl → i18next
- 모든 페이지의
"use client" 디렉티브 제거
next/link, next/navigation, next/dynamic → react-router-dom + React.lazy
전부 기계적인 치환이에요. Claude Code에 프롬프트 한 줄로 “이 프로젝트를 Next.js 16에서 Vite 8로 바꿔달라”고 넘겼고, 그대로 돌아갔어요.
NiceGUI부터 Vite까지 전체가 5일에 끝났어요. 3주 견적 대비 약 70% 단축한 거예요.
두 번을 거치면서 지킨 원칙
사실 이 글의 숫자 중 가장 자랑스러운 건 빌드 속도 8초에서 741ms가 된 것도 아니에요. 3주 견적이 5일이 된 것이요. 그리고 두 번을 옮기면서 꼭 지킨 원칙이 하나 있어요.
사용자는 프레임워크를 몰라야 한다.
리서처들 중 누구도 NiceGUI가 뭔지, Next.js가 뭔지, Vite가 뭔지 몰라요. 알 필요도 없어요. 그들에게 AED는 “어제 쓰던 Holdings 화면”이고, “오늘도 그대로 작동해야 하는 도구”예요.
그래서 이주할 때 이걸 지켰어요.
- URL은 1:1 매핑.
/backtest/detail/{alphaId} 같은 경로는 이주 후에도 그대로예요. 북마크, 공유 링크가 안 깨지게요.
- 디자인 토큰 이름은 고정. 앞에서 말한 CSS 변수 덕분에 컴포넌트 코드를 건드리지 않고도 디자인이 유지됐어요.
- 배포 공지 없이 배포. 사용자는 자고 일어나면 “AED가 더 빨라졌네?” 정도만 느끼게.
이주 끝나고 리서처 한 명이 말했어요.
“오 뭐 바꿨어요? 좀 더 빨라진 것 같은데?”
이게 성공이에요. 마이그레이션의 진짜 성공은 “사용자가 알아채지 못한 것”이에요.
이 프로젝트가 남긴 것
5일 스프린트에서 제가 가장 많이 배운 건 React도 Vite도 아니었어요. “이주를 이주 그 자체로 하면 안 된다”는 거였어요.
아무 준비 없이 NiceGUI를 열고 React로 한 페이지씩 옮겼으면, 아마 정말 3주가 걸렸을 거예요. 근데 그 3주가 5일이 된 건 이주를 위한 도구를 이주 전에 먼저 만들어뒀기 때문이었어요.
- 매일의 기획 결정을 PRD에 역류시켜두면, 이주 때 코드 대신 PRD를 읽으면 돼요
- 반복 작업을 Claude Code 스킬로 뽑아두면, 이주 때 그 스킬을 다시 쓸 수 있어요
- 디자인 토큰 이름을 의미 기반으로 고정해두면, 이주 때 디자인은 공짜로 따라와요
그리고 이주 중에 한 번 방향을 꺾는 결정도 배웠어요. 처음 정한 방향(Next.js)에 집착하지 않고, “왜 이걸 쓰고 있지?”라는 질문을 스스로 던질 수 있을 때, 진짜 맞는 도구에 도달할 수 있어요. Next.js를 시작한 지 며칠 되지 않아 Vite로 꺾은 건, 매몰비용을 인정하는 게 아니라 방향을 교정한 거였어요.
리소스가 없다는 건 핑계가 아니라 조건이에요. 개발자가 없으면 없는 대로, 디자이너가 없으면 없는 대로, 그 조건 안에서 어떻게 작업량을 1/4로 줄일지를 고민하는 게 기획자의 일인 것 같아요.
5일 스프린트가 끝난 다음 날, 한 글자 고치면 브라우저가 즉시 반응해요. 빌드가 8초에서 741ms가 됐고요. 이 느낌을 위해서 이주 전에 한 달간 쌓아둔 것들이 있었다는 걸, 이제는 잊지 않으려고요.



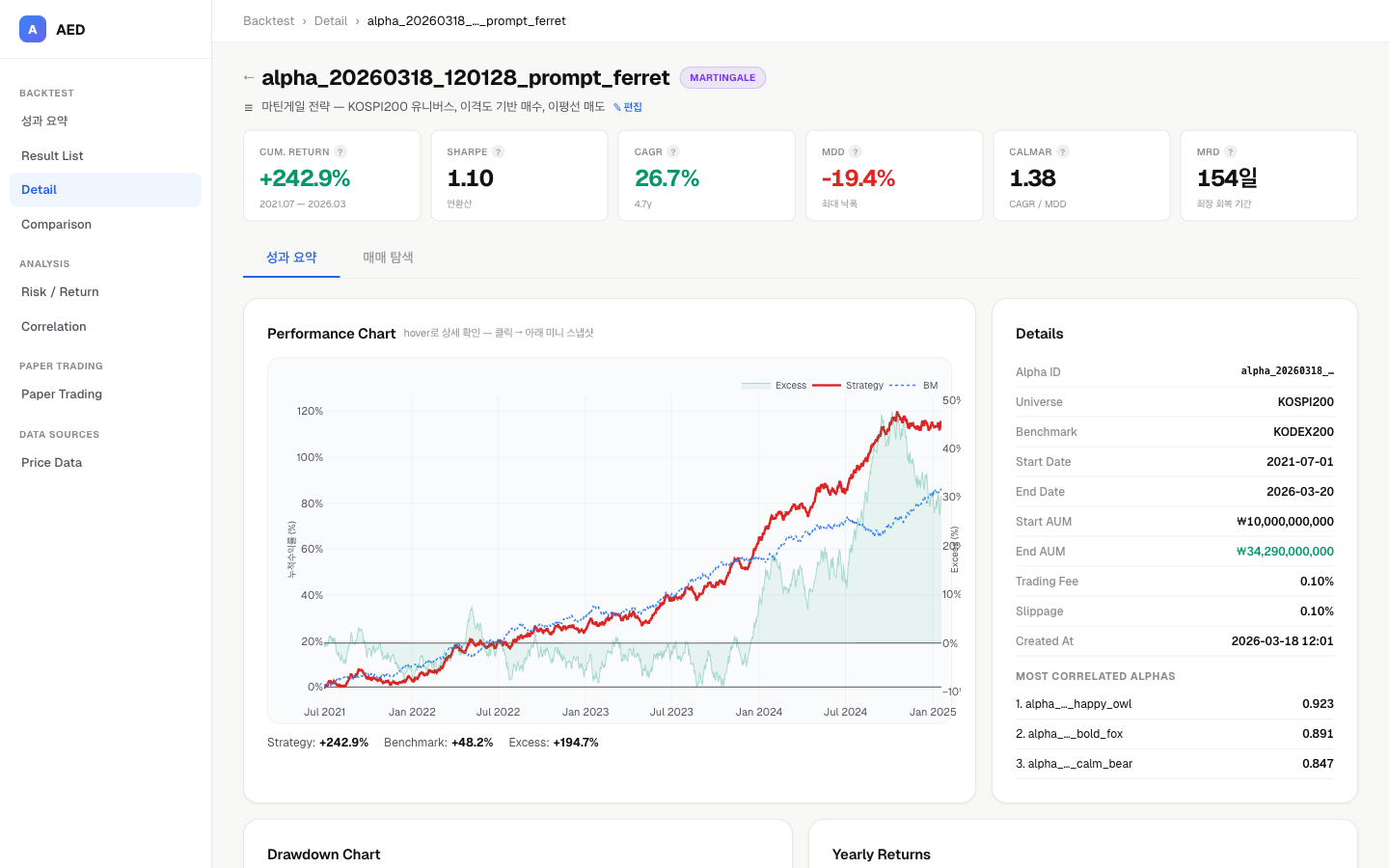 위 이미지는 실제 화면이 아닌 구성 예시입니다.
위 이미지는 실제 화면이 아닌 구성 예시입니다.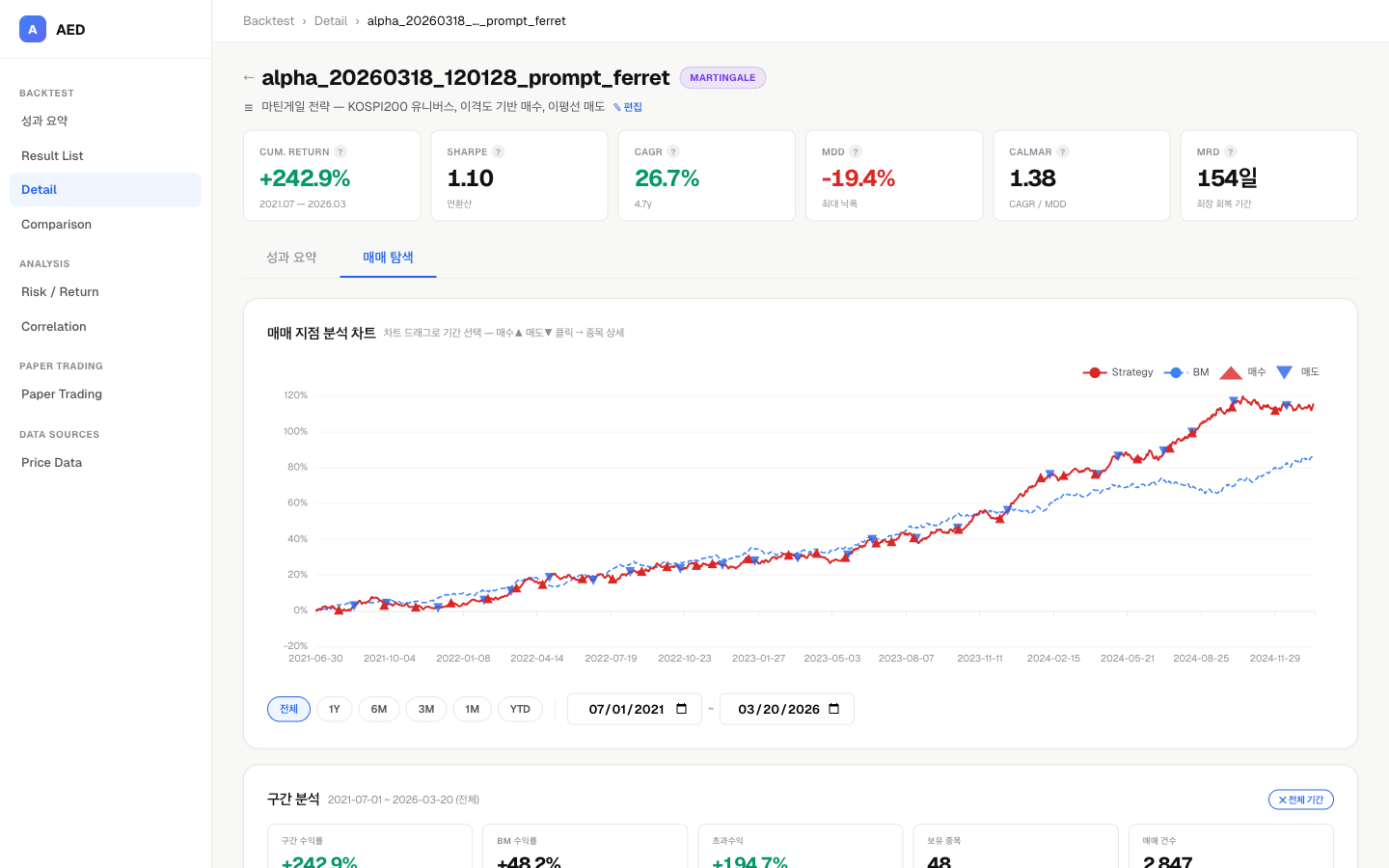 위 이미지는 실제 화면이 아닌 구성 예시입니다.
위 이미지는 실제 화면이 아닌 구성 예시입니다.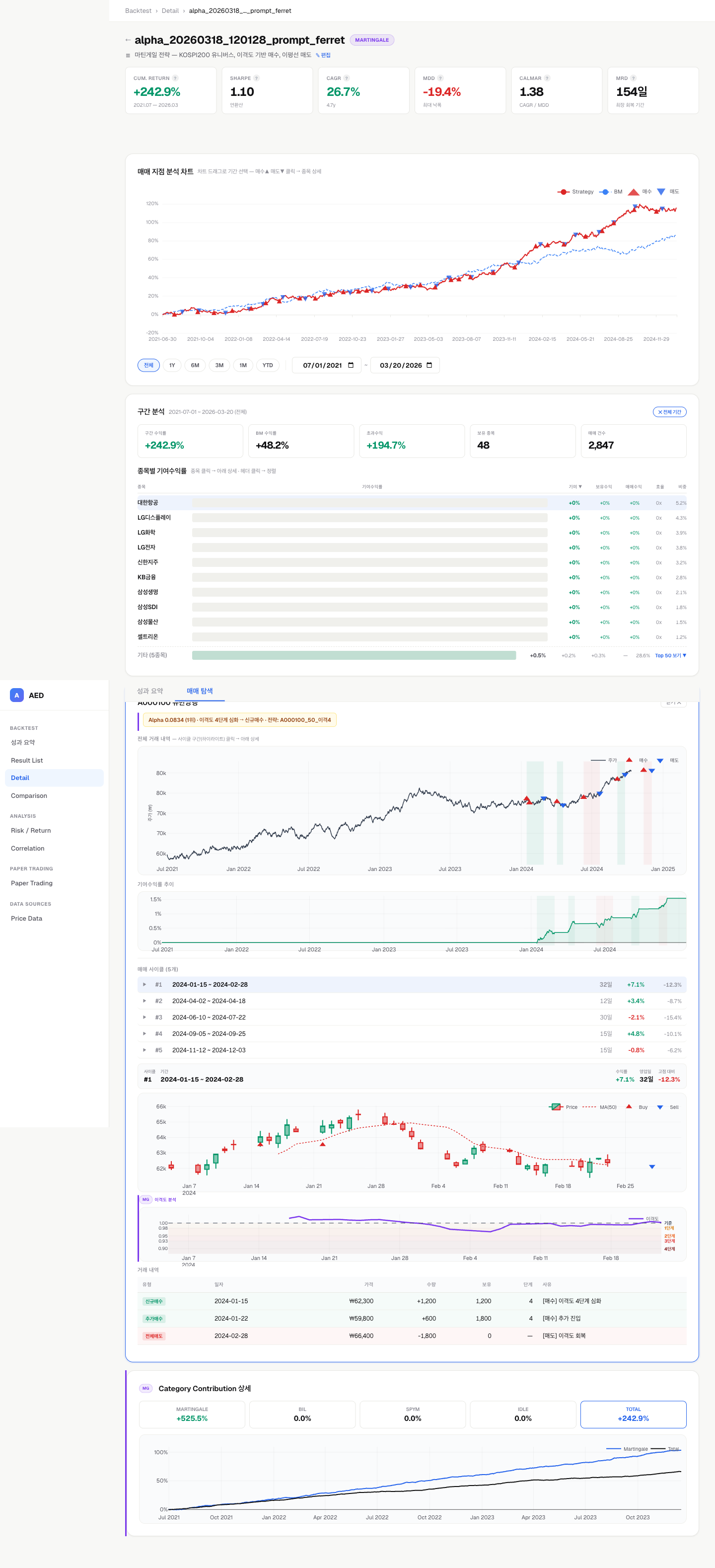 위 이미지는 실제 화면이 아닌 구성 예시입니다.
위 이미지는 실제 화면이 아닌 구성 예시입니다. 마감 5분 전. 30분 전까지 조용하던 3번 말에 갑자기 돈이 몰리기 시작했다.
마감 5분 전. 30분 전까지 조용하던 3번 말에 갑자기 돈이 몰리기 시작했다.
 핸드폰 4대에 각각 다른 데이터를 띄워놓고 실시간 분석 중.
핸드폰 4대에 각각 다른 데이터를 띄워놓고 실시간 분석 중.
 1800m 경주. 직선 구간에서 순위가 뒤집히는 걸 보면 심장이 멈춘다.
1800m 경주. 직선 구간에서 순위가 뒤집히는 걸 보면 심장이 멈춘다.